- There are 2 layer of neurons.
- Every neuron in the first layer is connected to every neuron in the second layer.
- Between each connection there is a weight.
- The neurons in the first layer can pick any values. They are the input neurons.
- The second (output) layer is computed by calculating the weighted sum of the input neurons for each of the output neurons. They can be true or false (0 or 1), so we apply a so-called activation function on them. For now, it is a Step function.
//Weight[j, i] is the weight from Input[j] to Output[i] neuron. Outputs[i] = Step(Sum(Input[j] * Weight[j, i] for j from 0 to Input.Length));
public static double Step(double d)
{
return d < 0.0D ? 0.0D : 1.0D;
}
The goal is to teach the network to map an input vector to an output vector. We can teach these networks by examples, input-to-output pairs. Then we should figure out the weights, which generate the desired output (also called target) from it's input pair in the example.The formula to update a weight is:
Weight[i, j] += LearningRate * (Target[j] - Output[j]) * Input[i];LearningRate is used for fine-tuning the weights, because of the characteristics of the gradient descent method (next part).
Also, there is a hidden bias neuron in the input layer, with a constant value of 1. From the link:
The bias can be thought of as the propensity (a tendency towards a particular way of behaving) of the perceptron to fire irrespective of its inputs.This cannot be modified by the user, but its weight is computed just for another input neuron.
So now the coding part...
Inputs and Outputs are arrays of doubles. The Weight layer is a matrix, with Inputs.Length in the first, and Outputs.Length in the second dimension. In C# it looks like:
double[] Inputs = new double[NumberOfInputs + 1]; //+1 for the bias Inputs[NumberOfInputs] = 1.0; //The bias is constant 1. double[] Outputs = new double[NumberOfOutputs]; double[,] Weights = new double[Inputs.Length, Outputs.Length];
//Weights[i, j] is the weight between Input[i] and Output[j]
Keep in mind that if you fill your inputs, you should only set Inputs.Length - 1 values (and leave the bias alone). So to calculate the output in C#:
public override double[] CalculateOutput(params double[] inputs)
{
if (inputs == null) return Outputs; //Outputs is the last neuron layer, it is an array of doubles
FillInputs(inputs); //it does range checks and fills a number of input neurons with the values given in the parameters
Parallel.For(0, Outputs.Length, i => //the neuron loop can go in parallel in a layer. In case of a multilayer perceptron, the values are propagated from the first to the last layer
{
Outputs[i] = 0;
for (int j = 0; j < Inputs.Length; j++)
Outputs[i] += Inputs[j] * SingleLayerWeights[j, i];
Outputs[i] = Step(Outputs[i]); //apply step function to clamp the value to 0 or 1.
});
return Outputs;
}
And how to train it? Using backpropagation, but in case of a single-layer system, it becomes the delta rule. I only share the code, you can also find the formula in the link above. We pass the inputs, and the target outputs, and let the code modify the weights to get the outputs right. This way if we present new input to the system, it can also classify it based on the rules learned from the previous examples.public override void Teach_Backpropagation(double[] inputs, double[] targets)
{
if (inputs == null || targets == null) return;
FillInputs(inputs);
var maxLoop = Math.Min(targets.Length, Outputs.Length); //bound checking
Parallel.For(0, maxLoop, i =>
{
Outputs[i] = 0;
for (int j = 0; j < Inputs.Length; j++)
{
Outputs[i] += Inputs[j] * SingleLayerWeights[j, i];
}
Outputs[i] = Step(Outputs[i]); //the block above is just the CalculateOutput function, but I can calculate it during the learning algorithm, and save another loop
//This is the real part: it trains the weight to reproduce the target values.
var diff = targets[i] - Outputs[i];
for (int j = 0; j < Inputs.Length; j++)
SingleLayerWeights[j, i] += LearningRate * diff * Inputs[j];
});
}
These networks are used for linearly-separable problems. It means, that if we represent our input vector in space as dots, (in case of 2 inputs, it can be a 2D cartesian coordinate-system). If the output of this system is 1 (true), make the dot black, else make the dot white. If you can draw a line to separate the black and white dots, the perceptron can also do this. An example is the logical-and and the logical-or operators: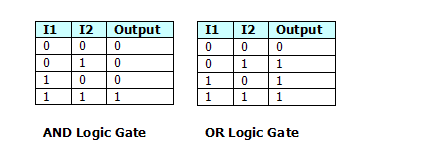
2 input neurons, 1 bias and 1 output neuron.
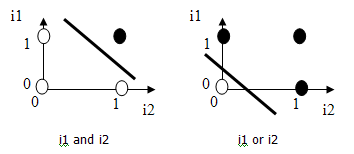
(The pictures are taken from the second link)
If you type another number, it will tell you wether it is positive or negative.It will be precise if you take numbers close to 0 from each side, because the system will draw the line according to the example values, and you should teach the system the precise bounds of the true and false parts of the space. This can be scaled to higher dimensions too, with 3 or more inputs, and outputs.
No comments:
Post a Comment